De l'alerting à base de logs v2
Rédigé par dada / 06 novembre 2020 / Aucun commentaire
À l'époque, mi-février 2020, je découvrais les pipelines de Promtail, une façon rudimentaire de parcourir des logs, d'y chercher ce qu'on veut et de déclencher une alerte si besoin. C'était ma v1 de l'alerting à base de logs.
Dans les faits, ça marche bien, mais ce n'est pas vraiment simple à mettre en place et ça demande des bidouilles pas possible quand on commence à vouloir trifouiller dans des choses plus complexes, comme Docker.
Il y a quelques semaines, j'ai découvert qu'il y avait un moyen encore plus simple et mieux intégré pour faire de l'alerting avec Grafana / Loki / Promtail : Loki lui-même.
Configurer Loki comme Datasource de type Prometheus
Si vous avez l'habitude de jongler avec toute cette stack, le titre de cette partie devrait vous faire tilter. C'est pourtant ce qu'il faut faire : pour Grafana, Loki va se la jouer Prometheus.
En version texte :
- Name : ce que vous voulez
- URL : http://localhost:3100/loki
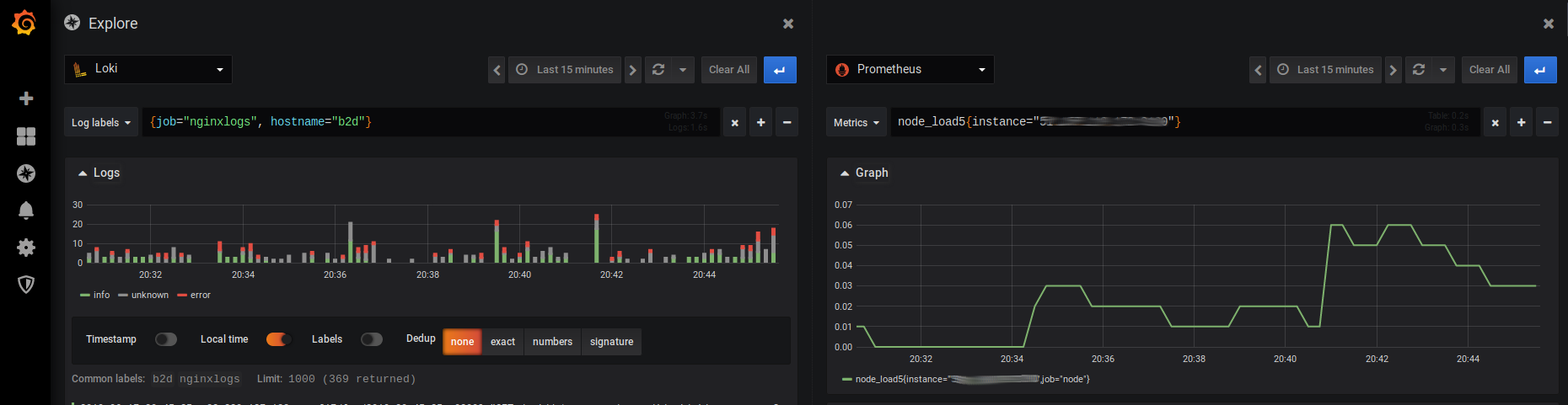
Dans la partie Explore de Grafana, vous deviez maintenant avec PromLoki comme Datasource :
Et c'est à partir de maintenant qu'on peut commencer à jouer !
Créer un panel lié à une alerte
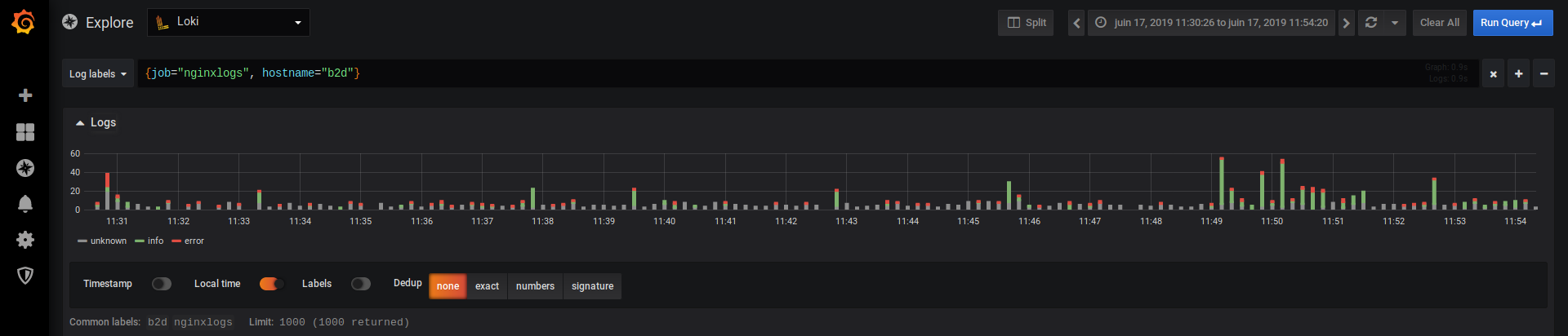
On va s'amuser à créer un panel pour analyser les logs qui nous intéressent.
Notez qu'on a bien choisi PromLoki comme datasource.
Dans mon exemple, ce sont les logs de Pixelfed que je veux parcourir pour pouvoir agir en cas de production.ERROR :
count_over_time(({hostname="pixelfed"} |= "production.ERROR")[1m])Maintenant qu'on sait ce qu'on cherche, on va configurer les règles qui déclencheront les alertes.
Dans les Rules :
- Choisissez un nom.
- On évalue toute le 10s
- On évalue toute le 10s
Dans les conditions :
- When : on fait la moyenne en choisissant avg()
- Of : cliquez sur les variables entre les virgules pour préciser vos réglages
- Above : ici, j'attends plus de 3 occurrences pour déclencher une alerte
Si vous avez le coup d’œil, vous avez remarquez que les deux captures d'écran présentées ci-dessus ont une ligne rouge : c'est la limite de tolérance de l'alerte. En dessous, tout va bien, au dessus, c'est la fin du monde.
Recevoir les alertes
Maintenant que vous avez la possibilité de déclencher alertes, il faut les recevoir d'une façon ou d'une autre. Grafana peut se brancher à un paquet d'outil, de Telegram à Elements en passant par Discord et l'Alert Manager de Prometheus voire Grafana llui-même: faites votre choix !
Perso, je me sers de mon AlertManager, il me noie sous les mails en cas de souci et c'est très bien comme ça !