Loki : jouer avec ses logs dans Grafana
Rédigé par dada / 18 juin 2019 / 7 commentaires
Le 3 juin dernier est sortie la première version beta de Loki : la v0.1.0. J'attendais cette première version depuis un bon moment ! Depuis le FOSDEM, pour être précis. Grand fan de la stack Prometheus / Grafana, je bavais d'impatience de pouvoir mettre les mains dans un système d'agrégation de logs directement dans Grafana. On y est alors regardons comment ça se passe !
Loki
Loki se comporte comme Prometheus : c'est un logiciel que vous allez installer sur votre machine qui sert pour le monitoring de votre infrastructure et le laisser vivre sa vie. Comme son mentor, ou presque, il va falloir lui associer des exporters pour le gaver de données : Promtail.
Installation
Pour le moment, je me sers de Loki dans un conteneur docker, parce que c'est marrant et parce que voilà. Pour le faire tourner comme j'en ai envie, j'ai besoin de deux fichiers :
- le Dockerfile
FROM grafana/loki
COPY local-config.yaml /etc/loki/local-config.yaml
CMD ["/bin/loki", "-config.file=/etc/loki/local-config.yaml"]
- Les conf dans local-config.yaml :
auth_enabled: false
server:
http_listen_port: 3100
ingester:
lifecycler:
address: 127.0.0.1
ring:
kvstore:
store: inmemory
replication_factor: 1
chunk_idle_period: 15m
schema_config:
configs:
- from: 2018-04-15
store: boltdb
object_store: filesystem
schema: v9
index:
prefix: index_
period: 168h
storage_config:
boltdb:
directory: /tmp/loki/index
filesystem:
directory: /tmp/loki/chunks
limits_config:
enforce_metric_name: false
reject_old_samples: true
reject_old_samples_max_age: 168h
chunk_store_config:
max_look_back_period: 0
table_manager:
chunk_tables_provisioning:
inactive_read_throughput: 0
inactive_write_throughput: 0
provisioned_read_throughput: 0
provisioned_write_throughput: 0
index_tables_provisioning:
inactive_read_throughput: 0
inactive_write_throughput: 0
provisioned_read_throughput: 0
provisioned_write_throughput: 0
retention_deletes_enabled: false
retention_period: 0
Il n'y a pas grand-chose à raconter sur ces deux fichiers. J'ai volontairement réduit le Dockerfile au strict minimum puisque je ne m'en sers que pour copier la configuration de Loki directement dans le conteneur, histoire de réduire la liste des paramètres à son lancement.
Exécution
Pour lancer Loki, on va taper ça dans son terminal :
docker run -d -p 3100:3100 loki
Si tout s'est bien passé, vous devriez avoir un conteneur qui vous répond des politesses :
root@monito:~# curl 127.0.0.1:3100
404 page not found
C'est normal. Par contre, si vous avez autre chose, c'est pas normal.
Maintenant que Loki tourne comme un grand, il faut bien comprendre qu'il ne sert à rien sans son comparse Promtail.
Promtail
Installation
Pour installer Promtail, on va faire exactement comme avec Loki : un conteneur simple avec un peu plus de paramètres au lancement.
- Le Dockerfile :
FROM grafana/promtail
COPY docker-config.yaml /etc/promtail/docker-config.yaml
ENTRYPOINT ["/usr/bin/promtail", "-config.file=/etc/promtail/docker-config.yaml"]
- La conf dans docker-config.yaml :
server:
http_listen_port: 9080
grpc_listen_port: 0
positions:
filename: /tmp/positions.yaml
clients:
- url: http://IP_SRV_LOKI:3100/api/prom/push
scrape_configs:
- job_name: system
static_configs:
- targets:
- localhost
labels:
job: varlogs
__path__: /var/log/*log
Si vous avez le coup d’œil, vous devriez avoir remarqué que cette configuration ressemble furieusement à celle de Prometheus : surtout la partie scrape_configs. On y retrouve la conf des jobs, les targets, labels, etc.
Remarquez qu'ici, vous devez remplacer IP_SRV_LOKI par l'IP du serveur sur lequel vous avez effectivement lancé Loki.
Ici, Promtail va aller gratter tous les fichiers locaux se terminant par log dans le répertoire /var/log/ le tout en les classant dans le job system avec le label varlogs.
Locaux, vous dites ? Mais nous sommes dans un conteneur : par quelle magie est-ce possible ? En jonglant avec les volumes !
Exécution
On build le conteneur :
docker build -t promtail .
Dans ce cas simple, on peut lancer Promtail comme ceci :
docker run -d -p 9095:9095 -v /var/log:/var/log promtail
Voyez qu'on monte les logs locaux de la machine dans le conteneur, les rendant accessibles à Promtail. N'hésitez pas à jouer de exec -it pour vérifier qu'ils sont bien là.
On se retrouve avec un Loki capable d'être gavé et d'un Promtail qui, pour le coup, gave Loki. Chouette.
Grafana
Maintenant que les bases sont en place, allons dire à Grafana de nous afficher tout ça. Si, comme moi, Grafana tourne sur la même machine que Loki, ça va être facile. Il faut ajouter un nouveau Data Source local : http://localhost:3100.
Une fois que c'est fait, foncez jouer dans la rubrique Explore et faites votre sélection ! Bon, pour le moment, vous n'avez que les logs system d'une seule machine, mais c'est déjà ça. Si je vous montre le graphique des logs Nginx de ma machine principale, vous avez ce genre de chose :
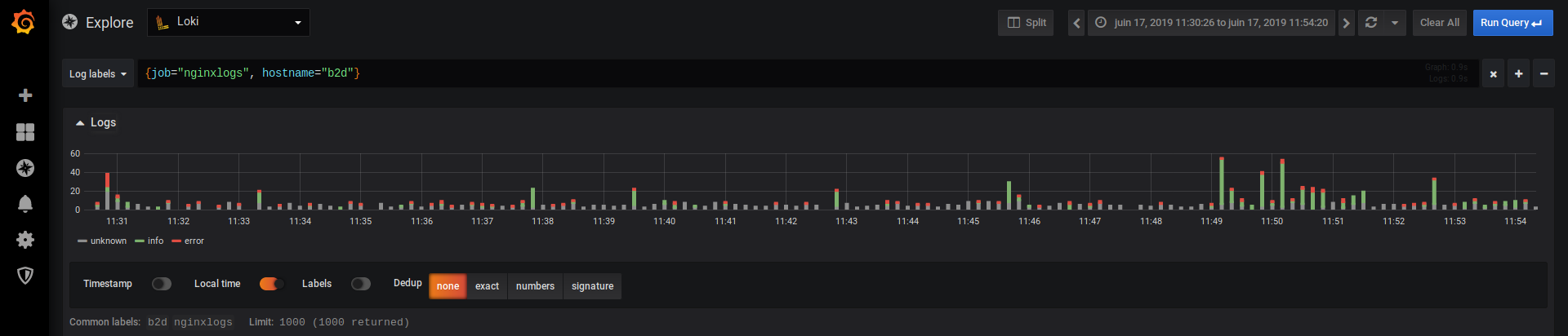
Si vous affichez cette capture d'écran en grand, vous devriez bien remarquer le manque de sérieux dans quelques-unes de mes configurations (rien de grave, rassurez-vous). On y voit du gris, du vert et du rouge.
Non, vous n'aurez pas les logs à proprement parler mais faites moi confiance, ils s'entassent en dessous.
L'affichage des logs est manipulable avec le Log Stream Selector. Ce machin permet de filtrer l'affichage simplement. Dans mon exemple, remarquez que je sélectionne le job nginxlogs et le hostname de ma machine.
Vous pouvez aussi filtrer le contenu même des logs, le texte en gros, mais je vais vous laisser chercher par vous-même.
Si vous avez vraiment le coup d’œil, dans la configuration de Promtail que je vous propose juste au dessus, il n'y a pas de hostname, ni de log Nginx d'ailleurs.
Pour que ça marche chez vous, vous devez déjà monter le répertoire de log de Nginx dans le conteneur et utiliser cette configuration :
- job_name: nginx
static_configs:
- targets:
- localhost
labels:
job: nginxlogs
__path__: /var/log/nginx/*log
hostname: b2d
Vous pouvez l'ajouter à la suite de ce que je propose déjà, ça vous fera déjà plus de logs à parcourir !
Bref. Afficher des logs dans Grafana, c'est chouette, mais Loki ne permet heureusement pas que ça sinon il n'y aurait aucun intérêt à parler d'un truc pas encore terminé.
Loki et Prometheus
Avoir un Loki en parallèle d'un Prometheus, ça permet de coupler la puissance des exporters Prometheus avec les logs pompés par Loki. Et ça, c'est beau ! Comment ? En cliquant sur "split" pour partager l'écran de Grafana en choisissant Loki d'un côté et Prometheus de l'autre.
En image ça donne quelque chose comme ça :
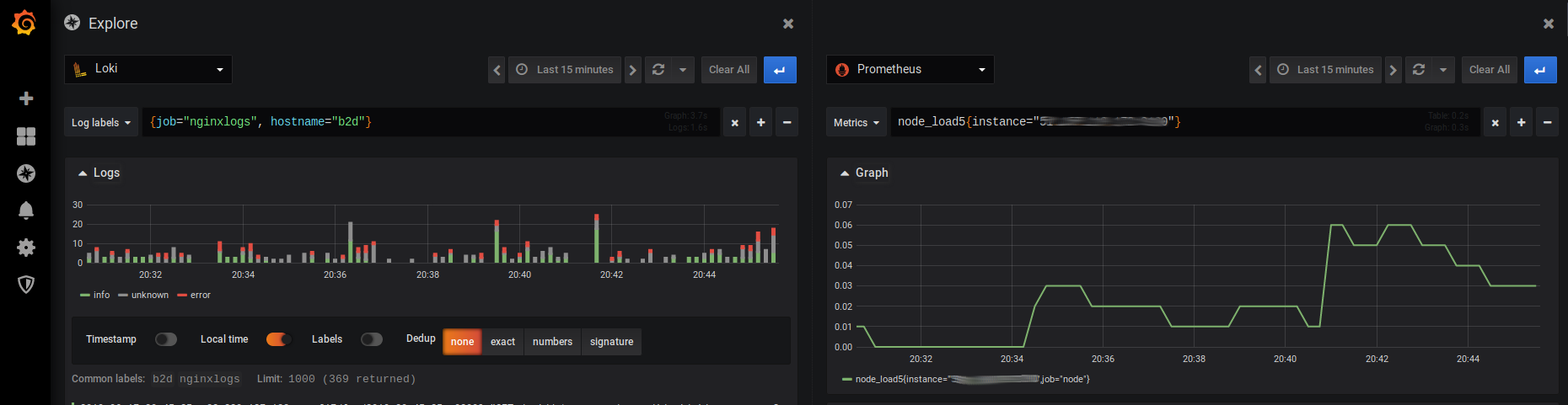
Ce qu'on y voit ? La corrélation entre les logs Nginx et le load de la machine. Bon, certes, ce n'est pas foufou mais je n'avais pas d'exemple super pertinent à vous montrer. Quoi qu'il en soit, cette combinaison Loki/Prometheus vous permet de mettre en image ce que vous voulez et ainsi réagir comme il faut, le tout avec un peu de PromQL et des filtres.
Deux yeux, un affichage unifié, c'est franchement cool. Et je ne vous parle pas encore de l'extase si vous avez bien fait l'effort de faire correspondre les labels entre les deux outils...!
Perso, je trouve ça absolument génial et j'ai hâte de continuer à approfondir ma maîtrise de ces beautés !