Et si on mettait PluXml dans un cluster k8s ?
Rédigé par dada / 11 novembre 2018 / Aucun commentaire
L'idée est saugrenue mais c'est exactement ce que j'ai fait ces derniers temps. Non sans souffrir, j'ai réussi à m'en sortir. Au programme : créer un conteneur qui va bien pour PluXml, mettre en place un déploiement pour le faire tourner dans k8s et l'utilisation de PersistentVolume.
Notez que je découvre toujours cet univers et que ce qui est présenté dans ce billet ne reflète que mes avancées.
La création du conteneur
Introduction
J'ai déjà pondu quelques conteneurs, principalement des exporters Prometheus en Python qui vont récupérer les statistiques de Mastodon et Pixelfed pour les afficher dans des dashboards Grafana (combo mots clés pour des recruteurs).
Pour PluXml, c'est différent. Il nous faut un conteneur avec :
- Les sources du CMS
- Du php7 et ses dépendances
- Un serveur web
Voyons comment y arriver en s'inspirant de ce qui a été fait pour Wordpress.
Le Dockerfile
C'est quoi ? C'est le fichier de configuration qui va nous permettre de créer le conteneur. En gros, les sources du conteneur.
FROM php:7.0-apache
WORKDIR /var/www/html
RUN apt update
RUN apt install -y wget unzip
RUN wget https://git.dadall.info/dada/pluxml/raw/master/pluxml-latest.zip
RUN mv pluxml-latest.zip /usr/src/
#VOLUME
VOLUME /var/www/html
RUN a2enmod rewrite
RUN service apache2 restart
RUN apt-get update && apt-get install -y \
libfreetype6-dev \
libjpeg62-turbo-dev \
libpng-dev \
&& docker-php-ext-install -j$(nproc) iconv \
&& docker-php-ext-configure gd --with-freetype-dir=/usr/include/ --with-jpeg-dir=/usr/include/ \
&& docker-php-ext-install -j$(nproc) gd
# Expose
EXPOSE 80
COPY entrypoint.sh /usr/local/bin/
ENTRYPOINT ["entrypoint.sh"]
CMD ["apache2-foreground"]
Comprendre le Dockerfile
FROM : C'est ici qu'on indique clairement la solution de facilité. Pour ne pas se battre avec l'installation d'Apache et de PHP7, j'indique au Dockerfile de prendre comme base un conteneur ayant déjà PHP7, Apache et Debian configurés.
WORKDIR : Ici, on indique où vont s’exécuter les commandes qui vont suivre. Ce n'est pas pertinent dans mon cas, mais bon.
VOLUME : C'est une sorte de point de montage entre le conteneur et son hôte.
RUN : Simple : les commandes que nous allons exécuter à la création du conteneur. Ici, on va récupérer les sources de PluXml qui sont hébergées dans mon Gitlab perso, les extraire et les préparer. On va aussi activer le module Apache nécessaire au bon fonctionnement du CMS et installer le module PHP-GD, lui aussi obligatoire.
EXPOSE : C'est le port qui sera ouvert vers l'extérieur. On va taper sur le port 80 pour accéder au contenu du conteneur.
COPY : Commande permettant de copier des fichiers de votre ordinateur à l'intérieur du conteneur. ici, le script entrypoint.
CMD : La commande à exécuter une fois que tout est terminé.
Note : Oui, je sais, il y a des choses inutiles. C'est un exemple.
Entrypoint ?
Le script :
#!/bin/bash
if [ ! -e index.php ]; then
unzip /usr/src/pluxml-latest.zip -d /var/www/html/
mv /var/www/html/PluXml/* /var/www/html
rm -rf /var/www/html/PluXml
chown -R www-data: /var/www/html
fi
exec "$@"
Comprendre le entrypoint
On est face à un script bash tout simple mais il demande un peu d'explication quand même.
Nous voulons un conteneur mettant à disposition les sources de notre CMS adoré ET qui stockera les articles, commentaires, images, etc, loin de ce-dit conteneur. Sans ça, une fois le conteneur mort, les données mourront avec lui. Ces données, pour faire simple, seront dans le fameux VOLUME cité un peu plus haut.
Au sujet des sources, si notre Dockerfile s'amusait à les mettre directement dans /var/www/html, comme la norme le voudrait, elles disparaîtraient dans k8s.
Pourquoi ? Parce que ce VOLUME sera géré par k8s lui-même et sera vide :
- Dockerfile dépose les sources dans le conteneur
- k8s charge le conteneur
- k8s monte son persistentVolume dans /var/www/html
- Les sources du conteneur disparaissent. Échec.
Si vous regardez bien le Dockerfile et ses incroyablement nombreuses lignes de code : il déplace les sources dans /usr/src, bien au chaud, à l’abri du problème. À la création du conteneur, dans k8s, le script regardera s'il existe un fichier index.php (issu des sources du PluXml) et, le cas échéant, copiera les fichiers manquants dans /var/www/html qui sera un PersistentVolume dans k8s ! Et c'est bien ce que nous voulons !
La création de l'image
Pour construire une image Docker, placez-vous dans les répertoires où vous avez déposé les 2 fichiers détaillés précédemment et :
docker build -t pluxml-5.6 .
Vous allez voir des lignes s'afficher dans tous les sens : pas de panique, c'est normal. Une fois votre terminal calmé :
Successfully built d554d0753425
Successfully tagged pluxml-5.6:latest
Gagné !
Téléverser l'image dans un dépôt
On ne va pas s'attarder là-dessus. Sachez juste que pour que k8s se serve de l'image, il faut qu'elle soit téléchargeable. J'ai poussé mon image dans le Docker Hub, dans un dépôt public. Vous allez pouvoir jouer avec sans vous prendre la tête.
Préparer Kubernetes
Postulats de base :
- Vous avez configuré Rook.
- Vous avez dégagé ce qui concerne les pods Wordpress/Mysql.
Le deployment & co
On va reprendre le travail vu ces derniers jours et créer des YAML pour notre conteneur !
dada@k8smaster:~/pluxml$ cat pluxml.yaml
apiVersion: v1
kind: Service
metadata:
name: pluxml
labels:
app: pluxml
spec:
ports:
- port: 80
selector:
app: pluxml
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: plx-pv-claim
labels:
app: pluxml
spec:
storageClassName: rook-ceph-block
accessModes:
- ReadWriteOnce
resources:
requests:
storage: 500Mi
---
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: pluxml
labels:
app: pluxml
spec:
strategy:
type: Recreate
template:
metadata:
labels:
app: pluxml
spec:
containers:
- image: dadall/pluxml-5.6:latest
imagePullPolicy: "Always"
name: pluxml
ports:
- containerPort: 80
name: pluxml
volumeMounts:
- name: pluxml-persistent-storage
mountPath: /var/www/html
volumes:
- name: pluxml-persistent-storage
persistentVolumeClaim:
claimName: plx-pv-claim
Vous remarquez que je ne me suis pas foulé : c'est le YAML de Wordpress légèrement retravaillé. On y trouve le nom de mon image dans le Deployment et un Service pluxml.
L'ingress
dada@k8smaster:~/pluxml$ cat pluxml-ingress.yaml
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
annotations:
kubernetes.io/ingress.class: nginx
name: pluxml-ingress
spec:
backend:
serviceName: pluxml
servicePort: 80
Là aussi, simple : l'ingress qui s'attache à l'application pluxml.
Vous créez tout ça :
dada@k8smaster:~/pluxml$ kubectl create -f pluxml.yaml
dada@k8smaster:~/pluxml$ kubectl create -f pluxml-ingress.yaml
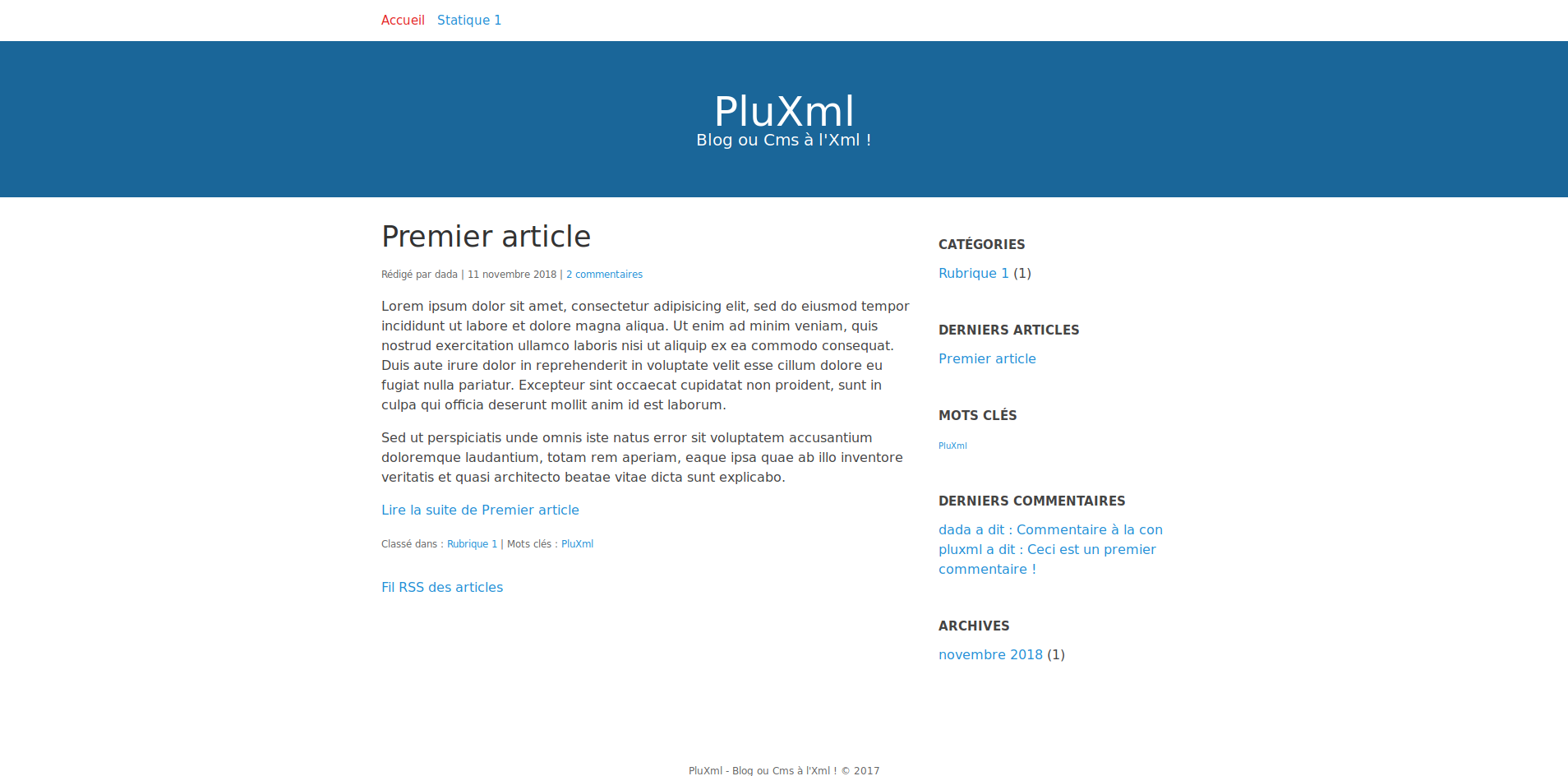
Si tout va bien, vous avez un pod PluXml qui vient d'apparaitre et qui est joignable !
Le pod :
dada@k8smaster:~/pluxml$ kubectl get pods --all-namespaces -o wide | grep plux
default pluxml-686f7d486-7p5sq 1/1 Running 0 82m 10.244.2.164 k8snode2 <none>
Le service :
dada@k8smaster:~/pluxml$ kubectl describe svc pluxml
Name: pluxml
Namespace: default
Labels: app=pluxml
Annotations: <none>
Selector: app=pluxml
Type: ClusterIP
IP: 10.100.177.201
Port: <unset> 80/TCP
TargetPort: 80/TCP
Endpoints: 10.244.1.31:80
Session Affinity: None
Events: <none>
L'Ingress :
dada@k8smaster:~/pluxml$ kubectl describe ingress pluxml
Name: pluxml-ingress
Namespace: default
Address:
Default backend: pluxml:80 (10.244.1.31:80,10.244.2.164:80)
Rules:
Host Path Backends
---- ---- --------
* * pluxml:80 (10.244.1.31:80,10.244.2.164:80)
Annotations:
kubernetes.io/ingress.class: nginx
Events: <none>
Coucou PluXml !