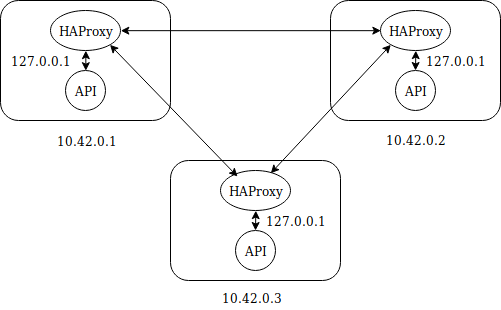
Récupérer ses flux RSS dans Firefox
Rédigé par dada / 02 janvier 2019 / 14 commentaires
Avec les dernières versions de Firefox, Mozilla a supprimé le support des flux RSS dans son navigateur. C'est un choix qu'on apprécie, ou pas, avec lequel il faut faire. J'ai décidé de configurer mon navigateur pour lui redonner la possibilité de jouer avec les flux RSS à travers l’application Want My RSS.
Installation
Pour l'installation, passez par ce lien pour télécharger et installer l'extension.
Utilisation
L'outil est assez simple. En naviguant dans le Web, vous verrez apparaître l’icône des flux RSS dans la barre d'adresse. Cliquez dessus et admirez la liste des flux disponibles.

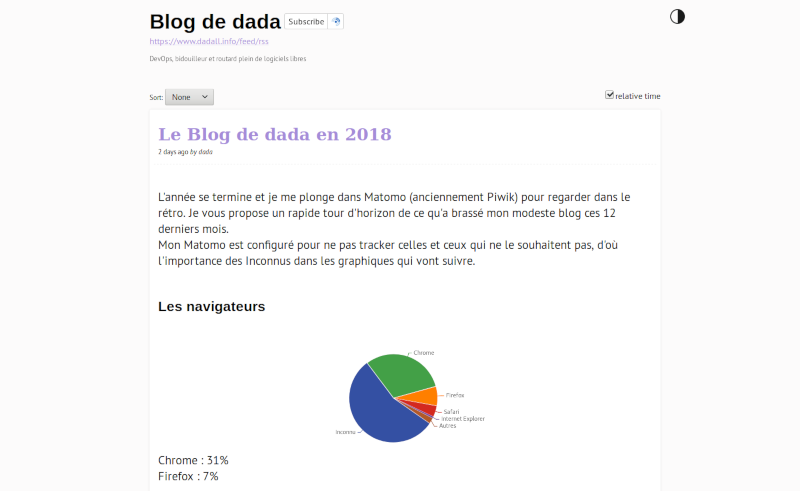
Chez moi, après avoir cliqué sur le flux des articles, ça donne :
Configuration
Want My RSS permet d'afficher les flux RSS mais aussi de les ajouter à son lecteur préféré. Chez moi, c'est FreshRSS qui tient le haut du pavé. Pour vous permettre d'ajouter un flux, configurez l'extension pour aller directement taper dans votre lecteur :
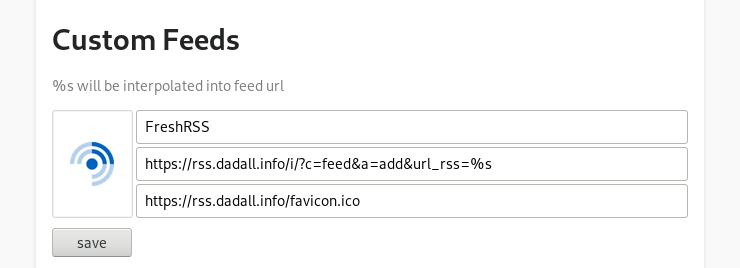
Si vous cherchez le lien qui va bien de votre FreshRSS, retrouvez-le dans Gestion des abonnements -> Outils d'abonnement.
Et voilà, les RSS sont de retour dans Firefox !