Si on regardait les bots des moteurs de recherche
Rédigé par dada / 08 février 2021 / 3 commentaires
Il y a un peu plus d'un an, je me suis amusé à comparer les moteurs de recherche en analysant leur capacité d'indexation sur mon blog. À l'époque, l'affaire de l'index de Qwant battait son plein : on se demandait qui étaient ces moteurs de recherche à l'indépendance douteuse.
Parler de moteur de recherche, qu'il soit éthique, écologique ou encore respectueux de la vie privée, c'est un foutoir sans nom. Notez que Lord s'est lancé dans la bataille et je vous invite à lire son billet. Il a pris le temps de vous expliquer en quoi on se fait toutes et tous avoir, plus ou moins.
Bref, ici, j'ai envie de vous partager le fruit d'une partie de mon travail en vous montrant la fréquence de passage des robots des différents moteurs de recherche. Oui, je mets en place des machins qui dépiautent les logs dans tous les sens possibles. Mais jamais pour un usage commercial !
Méthode : J'ai lancé une requête simple dans Grafana/Loki qui remonte les occurrences des différents bots dans les logs d'accès à mon blog tout le long du mois de janvier, avec un maximum de 5 000 requêtes*.
Note : L'intégration des images dans PluXml n'est pas parfaite, du coup, pensez à les clic droit Afficher l'image.
Note 2 : Les échelles sont différentes en fonction des graphiques. Oui, je sais, c'est pas top !
Duckduckgo

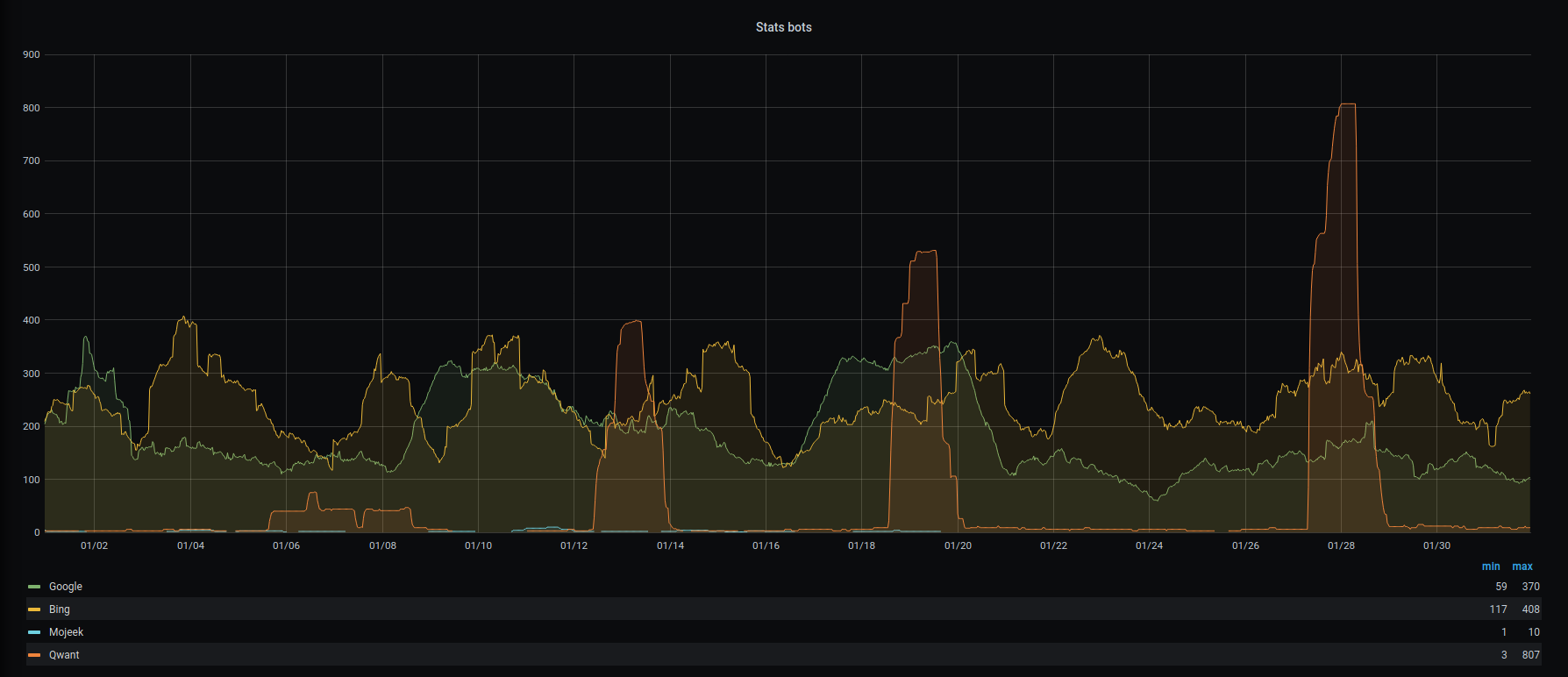
Ce moteur de recherche** n'est passé que deux fois me faire des coucous. Deux fois assez terribles puisqu'on remarque 2 pics d'un peu plus de 250 requêtes en quelques secondes.
En regardant ce qu'il a récupéré, je peux vous dire que ce n'est pas jojo : ça ne concerne que le thème de ce site.
Qwant

Avec le champion européen, on se rend compte qu'il bosse un peu plus que DDG. J'ai 2154 requêtes (avec un pic à 542 !) espacées de plusieurs jours. C'est un peu mieux au niveau de la diversité des infos relevées : Qwantify s'est promené un peu partout dans les articles, les images et même les flux RSS des commentaires.
Bing

Avec Bing, on arrive à ce que j'imagine être la quantité de travail d'un moteur de recherche. On est entre 30 et 100 requêtes par jour, tous les jours. C'est clairement trop pour mon petit site qui n'est pas mis à jour aussi souvent. Pour un site professionnel, ou un machin à buzz type Ouest-France ou 20Minutes, ça doit être important.
Mojeek

Je dois avouer que je ne pensais pas le trouver, ce nouveau moteur de recherche britannique. Il passe de temps en temps, principalement pour analyser mon robots.txt ! Bon, il se veut écolo, respectueux de la vie privée et surtout très jeune. En poussant un peu mes recherches, j'ai découvert qu'il était passé chez moi pour la première fois le 22 août 2020.

Le Patron : le GoogleBot. Je suis surpris de ne pas le voir plus tranchant que le robot de Bing. C'est pas flagrant : les deux touchent les limites de mon test : 5000 requêtes. Comme pour Bing, quel est l'intérêt de passer si souvent ? Mystère.
Comparaison
En plus du graphique ci-dessous, je vous offre un instantané plus joli pour mettre tout ça en perceptive.
Conclusion
Non, pas de conclusion. Ce que je vous montre n'est qu'un coup d’œil à un instant donné. Comme il est impossible de savoir vraiment ce qui peut déclencher le retour d'un bot sur tel ou tel site, il est impossible de comprendre la fréquence de passage d'un bot. Ici, je me fends d'un billet une ou deux fois par mois : autant dire qu'un passage par mois est largement suffisant pour indexer tout le contenu. Rien ne justifie 30 ou 200 requêtes par jour.
Enfin voilà, des bisous
* Pourquoi un maximum de 5 000 ? Parce que Googlebot.
** Pas vraiment, mais bon.