Accéder au cluster k8s depuis l'extérieur
Rédigé par dada / 09 novembre 2018 / Aucun commentaire

Perdu ?
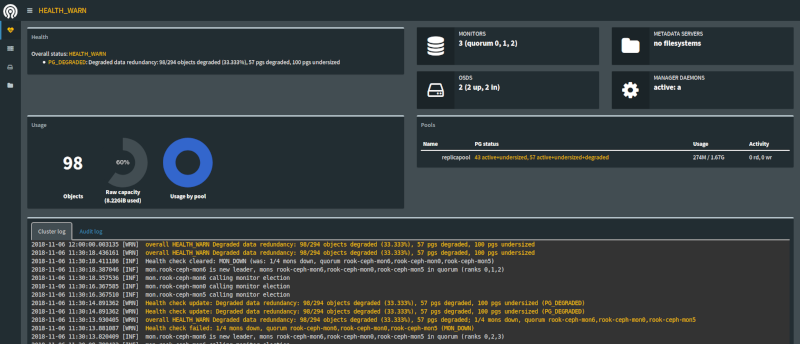
On vient de se battre pour mettre en place un cluster Ceph opérationnel, histoire de stocker ses données dans le cluster k8s et de les répliquer un peu. Maintenant que c'est bon, si on s'attaquait à des choses un peu plus visible, hors dashboard ?
Au programme de ce billet : Ingress, Service, Wordpress, des nouveaux pods.
Ingress Nginx
Cette chose-là va être le point d'entrée de notre cluster. Il va permettre à l'extérieur d'aller regarder à l'intérieur. Son rôle va être de comprendre la requête d'entrée et de l'orienter vers le pod qui y répondra. Dans le cas qui va suivre, aller sur l'IP du cluster pour y retrouver un Wordpress.
Installation via Helm
Comme on s'en sert déjà, on va continuer :
helm install stable/nginx-ingress --name my-nginx
Cette installation va faire apparaître les pods suivants :
dada@k8smaster:~$ kubectget pods -n default
NAME READY STATUS RESTARTS AGE
my-nginx-nginx-ingress-controller-565bc9555b-pcqjz 1/1 Running 2 8h
my-nginx-nginx-ingress-default-backend-5bcb65f5f4-728tx 1/1 Running 2 8h
Et un service. On n'a pas encore parlé de services : je vous redirige vers la documentation officielle si vous voulez en savoir bien plus.
dada@k8smaster:~$ kubectl --namespace default get services -o wide -w my-nginx-nginx-ingress-controller
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
my-nginx-nginx-ingress-controller LoadBalancer 10.100.45.147 <pending> 80:32462/TCP,443:30337/TCP 8s app=nginx-ingress,component=controller,release=my-nginx
Ça veut dire que l'Ingress Controller est bien installé. Notez le <pending> : ça veut dire que notre controller n'a pas d'IP externe. En gros : il ne sert à rien. Il lui faut une IP pour que nous puissions l'attaquer.
Dans une installation chez des gros fournisseurs d'informatique dans les nuages, nous aurions une sorte de plugin nous fournissant déjà l'IP tant désirée. Avec notre infrastructure sous Virtualbox, il va falloir faire autrement. Et autrement, ça veut dire avec MetalLB.
MetalLB
MetalLB, ce sont des pods que nous allons installer dans notre cluster et qui nous serviront à palier le problème cité juste au dessus. Il ira interroger notre DHCP, la Freebox dans mon cas, pour récupérer une IP publique.
Installer MetalLB
Toujours avec Helm :
helm install --name metallb stable/metallbUn peu d'attente et vous devriez voir de nouveaux pods :
dada@k8smaster:~$ kubectl get pods -n metallb-system
NAME READY STATUS RESTARTS AGE
controller-765899887-ck6bv 1/1 Running 2 8h
speaker-jdqg9 1/1 Running 2 8h
speaker-t4vtk 1/1 Running 2 8h
Il lui manque un fichier de configuration pour nous offrir une adresse IP externe :
apiVersion: v1
kind: ConfigMap
metadata:
namespace: default
name: config
data:
config: |
address-pools:
- name: default
protocol: layer2
addresses:
- 192.168.0.50-192.168.0.60
Les adresses IP en bas de ce fichier de conf vont permettre à MetalLB d'aller titiller notre DHCP (Freebox pour moi) pour obtenir une adresse. Quelque chose entre 192.168.0.50 et 192.168.0.60 dans mon cas. Vérifiez bien la configuration de votre Freebox avant de choisir une plage d'IP.
On l'applique :
kubectl create -f config.yaml
Retour à l'Ingress Nginx
Une fois après avoir configuré MetalLB, vous allez vérifier l'état du service :
dada@k8smaster:~/$ kubectl --namespace default get services -o wide -w my-nginx-nginx-ingress-controller
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE SELECTOR
my-nginx-nginx-ingress-controller LoadBalancer 10.100.45.147 192.168.0.50 80:32462/TCP,443:30337/TCP 3d3h app=nginx-ingress,component=controller,release=my-nginx
Vous avez vu ? Une EXTERNAL-IP ! On va pouvoir taper dessus !